“Yüksek Hızlı Veri İşleme Dünyası: Kafka ile Tanışın”
Bu yazımızda, mikroservis mimarisi ile birlikte sıklıkla duyduğumuz Apache Kafka yapısını ele alacağız. Yazımızda Kafka nedir, içeriğinde hangi kavramlar vardır gibi konulara değineceğiz.
Kafka Nedir?
Genel olarak Kafka’yı tanımlamak gerekirse, gerçek zamanlı verilerin anında işlenmesini sağlayan açık kaynak bir platformdur. Daha detaylı bir şekilde ifade edersek, Kafka büyük verilerin dağıtık bir sistem aracılığıyla kuyruk yapısı ile iletilmesini sağlar.
Neden Kafka’ya İhtiyaç Duyarız?
Kafka’ya olan ihtiyaçlarım ilk olarak mikroservisler arasında ortaya çıktı. Farklı mikroservisler arasında iletişim ve haberleşme gibi durumları çözmek için Kafka’yı kullandım. Ancak Kafka, sadece bu alanlar için değil, büyük veri aktarımları, farklı veritabanları arasında veri akışının sağlanması ve sistem performanslarını loglamak gibi çeşitli amaçlar için de kullanılabilir.

Tabii, Kafka’da kullanılan kavramları ele alalım ve basit anlaşılır şekilde açıklayalım:
1. Topic
Topic için SQL tablosu benzetmesi yapabiliriz. Her bir topic, belirli bir isme sahip olan ve verilerin depolandığı bir “kayıt defteri” olarak düşünülebilir. Topic’lerde veri setleri üreticiler (producers) tarafından yazılır ve tüketiciler (consumers) tarafından kullanılır. Her topic, key-value mantığına göre organize edilmiş binary formatında verileri tutar.
Topic İle İlgili Bilinmesi Gerekenler:
- Mesaj Güncelleme (Immutable Nature): Kafka’da bir kez yazılan mesajlar değiştirilemez. Ancak, aynı anahtar (key) ile yeni bir mesaj yazarak güncelleme yapılabilir. Bu sayede tüketiciler en güncel veriyi alabilir.
- Mesaj Silme (Tombstone Messages): Kafka’da mesajlar silinebilir. Genellikle bu işlem “tombstone” mesajları göndererek yapılır. Tombstone mesajlar, anahtar ile birlikte boş bir değer içerir ve tüketicilere eski mesajların artık geçerli olmadığını bildirir.
- Retention Policies (Saklama Politikaları): Kafka, mesajların belirli bir süre sonra otomatik olarak silinmesini sağlayan saklama politikaları sunar. Örneğin, mesajlar belirli bir zaman dilimi (zaman tabanlı saklama) veya belirli bir boyuta ulaştığında (boyut tabanlı saklama) silinebilir.
- Log Compaction (Günlük Daraltma): Kafka, belirli anahtarlarla ilişkili eski mesajları silerek yalnızca en son versiyonlarını saklayan bir süreç sunar. Bu özellik, özellikle veri güncellemeleri için kullanışlıdır ve disk alanından tasarruf sağlar.
2. Partition (Bölüm)
Partition, Kafka’da topic’lerin daha küçük alt kümelerine bölünmesidir. Her bir partition, belirli bir sıra ve depolama alanında verilerin sıralı olarak işlenmesini ve saklanmasını sağlar. Kafka’da partition’lar, veri akışlarının paralel olarak işlenmesini ve depolanmasını sağlayan önemli bileşenlerdir.
Partition ile İlgili Bilinmesi Gerekenler
Mesajlar ve Offset’ler
Her partition’daki mesajlar sıralıdır ve her bir mesaj bir offset ile tanımlanır. Offset, mesajın ilgili partition içindeki konumunu belirler. Bu sayede tüketiciler (consumers), mesajları belirli bir sırayla okuyabilirler. Offsetler, Kafka’nın mesajların sırasını korumasını ve tüketicilere doğru veriyi sunmasını sağlar.

Paralel İşleme
Partition’lar, verilerin paralel olarak işlenmesini sağlar. Bir topic’in birden fazla partition’a bölünmesi, bu topic’ten veri okuyan tüketicilerin de paralel olarak daha fazla işlem yapabilmesini sağlar. Örneğin, her partition farklı bir CPU çekirdeğinde veya farklı bir sunucuda işlenebilir. Bu özellik, Kafka’nın yatay olarak ölçeklenmesine olanak tanır ve sistem performansını artırır.
Replica (Kopya) Kavramı
Her partition’ın birden fazla replica (kopya) olabilir. Replicalar, veri dayanıklılığını ve yüksek kullanılabilirliği sağlamak için kullanılır. Örneğin, bir partition’ın birincil bir replica’sı ve bir veya daha fazla ikincil replica’sı olabilir. İkincil replicalar, birincil replica’daki veriyi yedekler ve bir arıza durumunda hızlı bir şekilde hizmete geçebilirler.
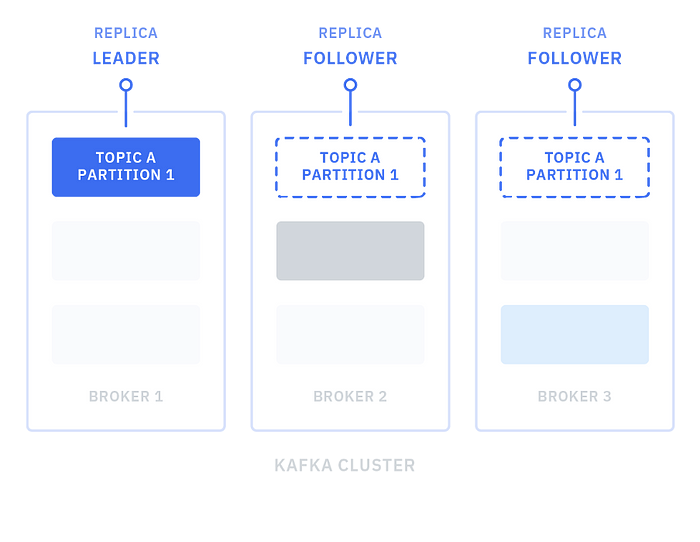
Bir partition’ın birincil kopyası (leader) ve bir veya daha fazla ikincil kopyası (follower) vardır. Leader, yazma ve okuma işlemlerini yönetir, follower’lar ise yedekleme ve arıza durumunda devreye girme amaçlıdır.
3. Broker
Broker’lar, Kafka sistemindeki temel bileşenlerdir ve veri saklama, işleme ve iletme süreçlerini yönetirler. Bir Kafka kümesinde birden fazla broker bulunabilir ve bu broker’lar birlikte çalışarak yüksek hacimli veri akışlarını yönetirler.
Broker İle İlgili Bilinmesi Gerekenler
- Veri Saklama ve Yönetim: Broker’lar, Kafka topic’leri ve partition’ları içindeki mesajları saklar ve yönetir. Her broker, kendisine atanmış partition’ların verilerini depolar ve bu verileri üreticilerden (producers) tüketicilere (consumers) ileten aracı görevi görür.
- Lider ve Takipçi Broker’lar: Her partition, bir lider broker ve bir veya daha fazla takipçi broker içerir. Lider broker, partition’a veri yazma ve okuma işlemlerini yönetir. Takipçi broker’lar ise lider broker’dan veriyi kopyalayarak yedekler. Bu yapı, veri güvenliğini ve yüksek kullanılabilirliği sağlar.
- Küme Yapısı: Kafka kümesinde birden fazla broker bulunur. Bu broker’lar, veri işleme yükünü ve veri saklama sorumluluğunu paylaşarak sistemin ölçeklenebilirliğini ve dayanıklılığını artırırlar. Her bir broker, küme içinde belirli bir görevi üstlenir ve diğer broker’larla işbirliği içinde çalışır.
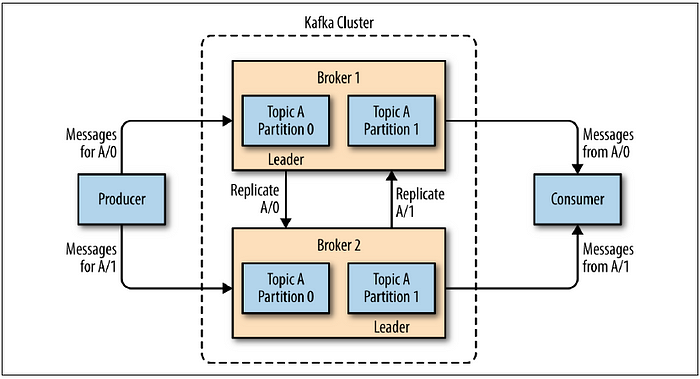
Çalışma biçimi;
Producer, belirli topic’lere mesajlar gönderir. Topic’ler, verilerin mantıksal olarak kategorize edildiği kayıt defterleridir. Producer, mesajları belirli bir topic’e ileterek Kafka cluster’ına gönderir.
Mesajlar, topic’e göre belirlenen bir partition algoritmasıyla bu partition’lara dağıtılır. Her partition, bir lider (leader) ve bir veya daha fazla takipçi (follower) olmak üzere broker’lar arasında bölüşülür.
Brokerlar ve Partition Yapısı:
- Brokerlar: Kafka kümesinde bulunan her bir fiziksel sunucu bir broker olarak adlandırılır. Brokerlar, partition’ların veri saklama ve yönetimini üstlenir.
- Leader ve Follower Brokerlar: Her partition, bir lider (leader) ve bir veya daha fazla takipçi (follower) broker’a sahiptir.
- Leader Broker: Lider broker, partition’a gelen mesajların yazılmasını ve tüketicilere gönderilmesini yönetir.
- Follower Brokerlar: Takipçi brokerlar, lider broker’dan gelen veriyi kopyalar ve güncel tutarlar. Bu yapı, veri güvenliğini sağlar ve yüksek kullanılabilirlik sunar.
Consumer: Consumerlar, belirli bir topic’ten veri okur. Her bir consumer, bir partition’dan veri okurken, partition içindeki veri sırasını koruyan offset bilgisini kullanır.
4- Producer
Bir veriyi Kafka’ya gönderen uygulamalara producer denir. Producer’lar, çeşitli kaynaklardan (örneğin sensörlerden, web uygulamalarından, veritabanlarından vb.) gelen verileri toplar ve bu verileri Kafka kümesine iletilmek üzere gönderirler.
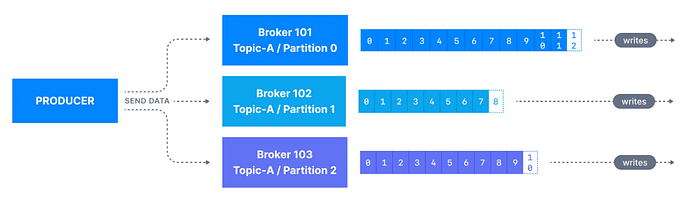
Süreç Nasıl İşliyor?
- Brokerlar ile Bağlantı Kurma: Producer tarafında, Kafka kümesindeki brokerlarla iletişim kurmanız gerekmektedir. Bu brokerlar, Kafka kümesindeki fiziksel sunucuları temsil ederler ve verilerin depolanması ve işlenmesi için gereklidir.
- Topic’e Mesaj Gönderme: Belirlenen topic’e mesaj gönderme işlemine başlayabilirsiniz. Her bir mesaj, key-value mantığına göre oluşturulur. Key belirtilmezse, mesajlar eşit şekilde partition’lar arasında dağıtılır ve bu durumda mesajların sıralı gittiği garanti edilir.
- Key Kavramı ve Partitionlar: Eğer bir key belirtirseniz, bu key’in bulunduğu mesajlar aynı partition’a yönlendirilir. Örneğin, ülke bilgisini key olarak belirtirseniz, tüm aynı ülkeye ait veriler aynı partition’da toplanır. Bu, verilerin daha öngörülebilir bir şekilde işlenmesini ve sıralı okunmasını sağlar.
- Örnek ile Açıklama: Örneğin, bir araba galerisi uygulamasında ülke, mağaza ve satış verilerini Kafka kümesine gönderiyorsunuz. Eğer key olarak ülke bilgisini belirtirseniz, tüm A ülkesine ait mağaza ve satış verileri aynı partition’a yönlendirilir. Böylece, A ülkesine ait verilerin sırasıyla işlenmesi ve okunması sağlanır.
- Key Kullanımının Nedeni: Key kullanımının ana nedeni, consumer’ların birden fazla partition’dan veri okuduğunda mesaj sırasının garantilenememesidir. Ancak, her bir partition içinde mesaj sırası garanti edilir. Bu nedenle, belirli bir anahtar kullanarak verileri gruplamak ve işlemek, uygulama performansını artırır ve veri bütünlüğünü korur.
5. Consumer
Consumer, Kafka’da mesajları okuyan ve işleyen uygulamalara verilen addır. Consumer’lar, Kafka brokerlarında saklanan mesajları tüketirler ve bu mesajları işleme süreçlerine dahil ederler.
Consumer’ların Temel Özellikleri:
Mesajları Okuma: Consumer’lar, Kafka brokerlarında saklanan mesajları belirli bir topic’ten (konudan) okur. Her consumer, belirli partition’lardan mesajları okur ve işler.
Consumer Group’lar: Kafka’da consumer’lar genellikle consumer group’lar (tüketici grupları) halinde organize edilirler.
- Tüketici Grupları: Her consumer group, belirli bir topic’in partition’larını paylaşarak mesajları işler. Bu, paralel işleme ve yük dağılımı sağlar.
- Partition Paylaşımı: Bir consumer group içindeki her bir consumer, belirli partition’lardan mesajları alır. Aynı partition aynı anda yalnızca bir consumer tarafından okunabilir, böylece veri bütünlüğü ve sıralama sağlanır.
Paralel İşleme: Consumer group’lar sayesinde, aynı topic üzerinde çalışan farklı consumer’lar paralel olarak mesajları işleyebilir. Bu, Kafka’nın ölçeklenebilirliğini artırır ve yüksek performans sağlar.
Mesaj Sırası: Her bir partition içinde mesajlar sıralı olarak saklanır ve okunur. Bu, Kafka’nın sıralı mesaj iletimini garantilemesini sağlar. Ancak, farklı partition’lar arasında mesaj sırası garanti edilmez.
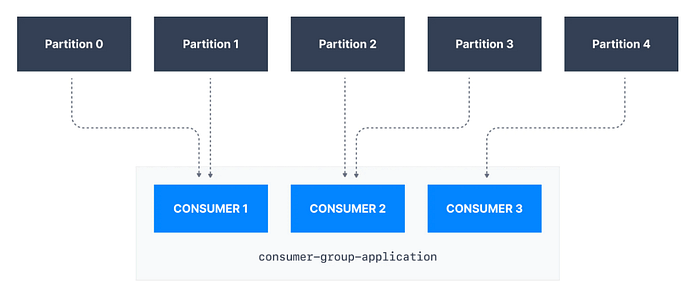
Aynı gruba ait consumer’ları belirtmek için group.id parametresini kullanabilirsiniz. Consumer sayısı partition sayısından fazlaysa, bazı consumer'lar inactive duruma geçecektir.
Consumer'larda en önemli unsur olan offset değeri, mesajın partition içindeki konumunu belirler.
Consumer'lar, hangi mesajları okuduklarını ve hangilerini okumadıklarını takip etmek için bu değeri kullanırlar.
Örneğin, Consumer 1, Partition 0'daki offset 1'e kadar olan mesajları işledi ve Kafka'ya commit etti. Bu durumda Kafka bu bilgiyi saklar ve Consumer 1 yeniden başlatıldığında veya çöktüğünde, kaldığı yerden devam ederek Partition 0'daki offset 2'den okumaya başlar.
6- ZooKeeper
ZooKeeper, temel olarak dağıtılmış sistemler arasında senkronizasyon, yapılandırma yönetimi ve isimlendirme hizmetleri sağlar. ZooKeeper’da bu kafka için yönetim ve dağıtım kısmında kullanılır.
- Kafka kümesindeki broker’ların (sunucuların) durumunu izler ve yönetir. Bu, broker’ların küme içindeki konumlarını ve durumlarını güncel tutar.
- Partition’lar için lider broker’ların seçiminde kullanılır. Her partition, verinin yönetimini ve replikasyonunu kontrol eden bir lider broker’a sahiptir. ZooKeeper, bu lider broker’ları seçer ve değişiklikleri yönetir.
- Eski sistemlerde offset bilgilerini ZooKeeper’da tutuluyordu. Yeni sistemle beraber kafka offset bilgisini kendi içerisinde tutuyor.
ZooKeeper ve Kafka, büyük veri işleme sistemlerinin temelini oluşturan iki kritik platformdur. Birlikte kullanıldığında, sağlamlık, ölçeklenebilirlik ve yüksek performans gibi önemli özellikler sunarak modern veri işleme ihtiyaçlarını karşılarlar.
Genel hatlarıyla kafka ve kavramlarını en basit haliyle aktarmaya çalıştım. Uygulamalarınızın hangi kısmında çözüm sağlayabileceğine değinmeye çalıştım. Okuduğunuz için teşekkürler :)

